This post will discuss the different ways XML Publisher can be used along with Microsoft Word Template builder to generate Reports.
XML Publisher (also called BI Publisher) has the following Deployment options1)
Oracle Applications (will not be discussed in this post)
2)
XML Publisher Desktop EditionInstalls XML Publisher Template Builder in Microsoft word that helps you build templates for your Reports. The templates can be stored as rtf files. Following are the Source Data Options using Template Builder in word
a)XML File
b)SQL Query , needs connection information to source database
c)XML Schema
d)XML generated by Siebel Analytics Answers (I have not been able to get this to work , it may be something that will be available in the next releases and more easily integrated in the next few releases of Siebel Analytics)
3)
XML Publisher Enterprise Editiona)provides a web based console that can be used to publish multiple reports
b)XML Publisher enables you to define your reports and separate the data from the layout of the reports .
c)XML Publisher can run on any J2EE compliant Application Server
XML Publisher Desktop Edition:If you have installed the Desktop Edition
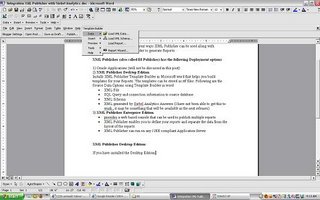
Template Builder Options will be available from MS Word menu.
Template Builder – Data – Load XML Data (XML File) , XML Schema , Report wizard (lets you give database connect information and the sql to extract the data)
Below will list a quick example on how the Report Wizard can be used (connecting to the hr schema to get a list of Departments)
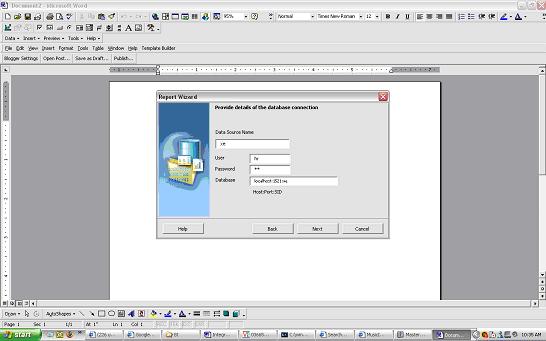
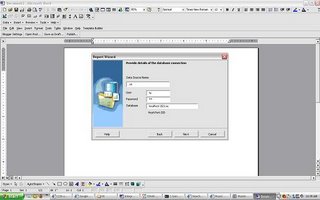 give the database connect information and sql query for the data that needs to be retrieved.We will choose the Default Template Layout in this example.
give the database connect information and sql query for the data that needs to be retrieved.We will choose the Default Template Layout in this example.
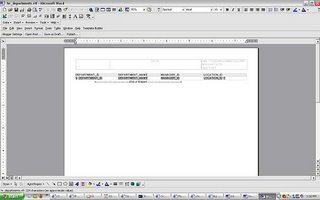 preview the Report and then save the RTF file (in this example we save the RTF file as hr_departments.rtf
preview the Report and then save the RTF file (in this example we save the RTF file as hr_departments.rtf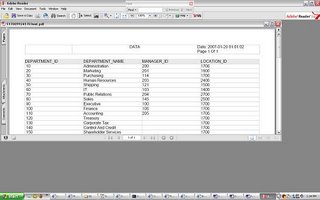 XML Publisher Enterprise Edition
XML Publisher Enterprise Edition
As mentioned XML Publisher enterprise edition can run on any J2EE compliant Application Server.
The Admin and Reports directories are available under
Install_dir/xmlpserver
The following files have the port numbers used by the application.
HTTP Port 15101 install_dir/default-web-site.xml
RMI Port 15111 install_dir/rmi.xml
JMS Port 15121 install_dir/jms.xml
Default URL to access XML Publisher Application http://host:15101/xmlpserver (default username/pwd admin/admin)
create new folder and new Report in the corresponding folder.
Edit the Report to define the following properties:
i)datasource for the Report (new datasources can be created in the Admin window)
ii)Data Model: Define the sql query
iii)New List of Values: If the Report uses LOV’s
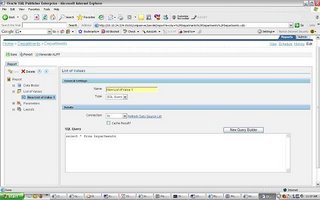 iv)Parameters: if any parameters are needed for the Report
iv)Parameters: if any parameters are needed for the Report
v)Layouts: create a new template called hr_departments
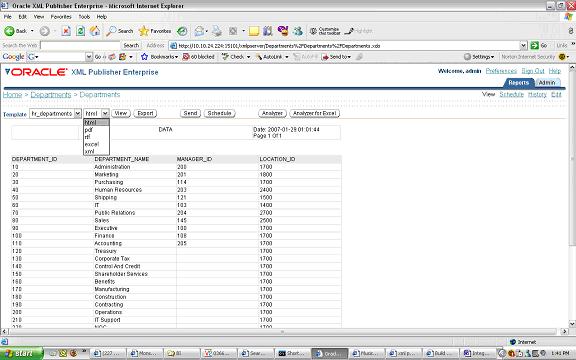
 upload hr_departments.rtf and tie it to the hr_departments template.View the results
upload hr_departments.rtf and tie it to the hr_departments template.View the results
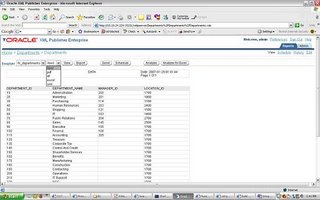 you can see that the template is chosen by default and the different output formats available. The above is a very simple illustration of how XML publisher will let your users design their own Reports(and manage changes to design templates of reports) while IT can focus on the data needed for the Reports and other important tasks.
you can see that the template is chosen by default and the different output formats available. The above is a very simple illustration of how XML publisher will let your users design their own Reports(and manage changes to design templates of reports) while IT can focus on the data needed for the Reports and other important tasks.








 give all the Power Center Server Registration Properties and define your PMRootDir
give all the Power Center Server Registration Properties and define your PMRootDir